First introduced by Google in 2016, tensor processing units (TPUs) have since become an essential tool for many machine learning applications. But what exactly are TPUs? And how do they work?
In this article, we’ll try to digest the complex topic of TPUs in a way that even a five-year-old could understand. So let’s get started!
What is a tensor processing unit?
Put simply, a tensor processing unit (TPU) is a type of computer chip that is designed specifically for machine learning tasks. These tasks include things like:
- Image recognition: “who is this in this photo?”,
- Natural language processing: “what does this text say?”,
- Predictive analytics: “how likely is this to happen?”,
— and many others.
Of course, these tasks can be performed by other types of computer chips too, like GPUs (graphics processing units) or even your home computer. However, TPUs are generally much better at machine learning tasks than either of these other types of chips.
How are tensor processing units different from other computer chips?
The main difference between TPUs and other computer chips is in their design. TPUs contain something known as “systolic arrays.” These are essentially long chains of processing units that are all connected together, like this:

If you’ve ever seen a matrix — the thing from math, not the movie — you’ll likely notice that a TPU looks a lot like one. And that’s because, in a sense, that’s what they are: matrix processors.
Systolic arrays allow TPUs to handle very large data sets quickly and efficiently. This is important, because machine learning tasks often involve working with very large data sets — which are, essentially, large matrices.
In contrast, GPUs are initially designed for graphics tasks. They, too, have certain features that make them good for matrix calculations, much more so than your home coputer. However, they don’t have it as the foundation of their design, which is why they can’t handle these tasks as well as TPUs.
How do tensor processing units work?
So, we know that TPUs are designed specifically for matrix computations. But how do they actually do these tasks?
Consider this simple example, which is often used to benchmark machine learning algorithms:

In this image, you can see a set of handwritten digits. The goal of a machine learning algorithm is to identify which of these digits is shown in the image.
When the machine learning algorithm is presented with an image like this, it will first convert the image into a row of numbers (pixel intensities) and then “move” these numbers across a neural network. In the end, it will output a single number, which is the index of the digit that was shown in the image.
The mechanism by which these numbers “travel” across the neural network is essentially series of operations with matrices: computation, multiplication, convolution, and so on.
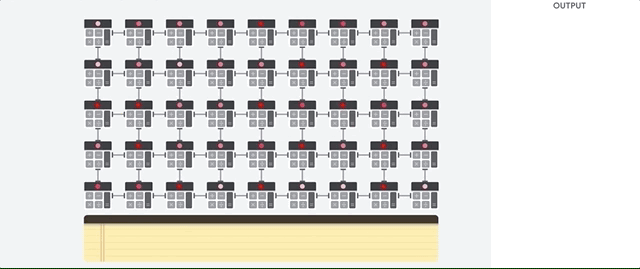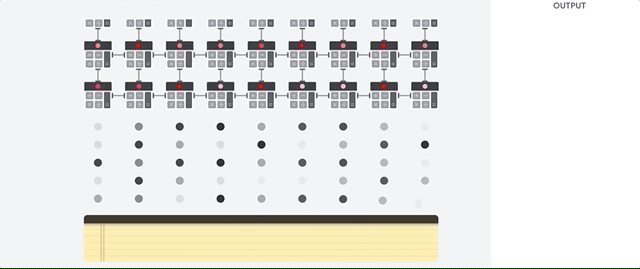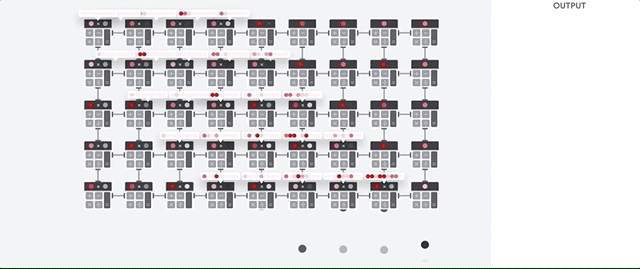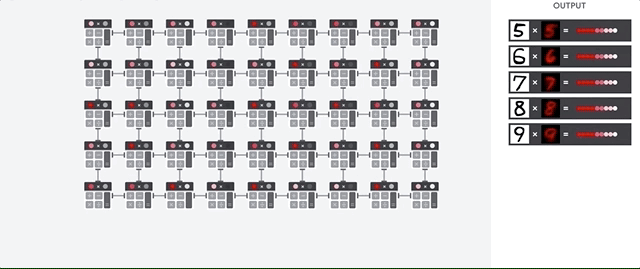
If it is a GPU or a CPU that is performing these operations, this will involve a lot of memory-related work: They need to load, store, and write back a lot of data. Naturally, all of this invovles a lot of time and energy.
In contrast, TPUs are specifically designed to handle this kind of matrix computation quickly and efficiently. They don’t even have to store or load anything, because all the needed information is right there in the systolic array!
Here’s a fancy animation to illustrate this:
As a result, TPUs are able to perform matrix computations in a blazingly fast manner.
What are the benefits of using tensor processing units?
The main benefit of using TPUs is that they can help you train machine learning models much faster than other types of computer chips. This is important, because the more data you can train on in a shorter amount of time, the better your model will be.
In addition, TPUs are also great for accelerating other machine learning tasks. For example, they can help you speed up “inference” — the part of machine learning that involves making predictions, or applying the results of a machine learning model to new data.
In general, TPUs are best suited for use cases that are:
- Dominated by matrix computations,
- Inolve large data sets, and
- Don’t involve custom, non-matrix calculations during principal training.
Are there any disadvantages to using tensor processing units?
Although TPUs are great for the vast majority of machine learning tasks, there are some workloads that they are not well-suited for. These include workloads that:
- Heavily rely on branching — that is, making decisions based on conditions that can’t be known in advance. TPU is a conveyor belt for matrix ops, not a decision engine.
- Contain many element-wise algebra operations — operations that involve only a small number of items at a time. These are for TPUs like shooting sparrows with a cannon.
- Work with sparse matrices — those that don’t have a lot of data packed into them. Such matrices can be handled pretty well by GPUs, so there’s no real need for TPUs.
- Require high-precision arithmetic — that is, calculations that must be very accurate. TPUs are designed for speed and efficiency, not being accurate to the last decimal point.
How do I get started using tensor processing units in my machine learning projects?
So far TPUs are predominantly associated with Google and its cloud services. Companies like Amazon, Microsoft, and NVIDIA are all making inroads into the TPU market, but for now, Google is still the dominant player. It means that if you want to use TPUs in your machine learning projects, the first step is to make sure that you have a Google Cloud Platform account.
Google TPU supports TensorFlow, JAX, and PyTorch, so you can use any of these frameworks to train your machine learning models on TPUs. If you’re not sure where to start, Cloud TPU quickstart tutorials will walk you through the process.
Are TPUs only meant for Cloud-based machine learning?
Although TPUs were originally designed for use with Google’s cloud services, the technology behind them is platform-agnostic. This means that TPUs can be used in a variety of environments, including on-premises servers and even edge devices — say, smartphones or self-driving cars.
In fact, Google has even developed an Edge TPU that can be used on devices like these. Companies like Intel, Graphcore and Fujitsu are also developing AI-specific processing units, although they do it under different names and with slightly different architectural designs.
Finally, some companies, like us here at Edged, are building not just chips, but “IP cores.” These are essentially designs that can be used by any chip manufacturer to make their semiconductor products “AI-ready.” This way, any company can build a TPU-powered device, regardless of their affiliation with any one particular manufacturer.
What are the future prospects for tensor processing units?
The future looks very bright for TPUs. They continue to gain in popularity due to their ability to speed up machine learning tasks and accelerate the development of new AI applications.
Of course, the technology is still relatively new, and there is a lot of room for improvement. For example, TPUs are not well-suited for all workloads, as we’ve discussed earlier. In addition, they can be quite expensive — although this is slowly changing as the technology matures and becomes more widely available.
Finally, as more and more companies enter the market, we can expect to see a wider variety of TPUs with different capabilities — which will only make them more useful for a wider range of tasks.
All in all, TPUs are a very exciting technology, and we can’t wait to see what the future holds for them!
Related articles: